
AI 지적 능력 기존 벤치마크 차례로 능가
똑똑한 인간 1000명이 낸 '마지막 시험'
o1, 딥시크R1, 제미나이 모두 10점 미만
퍼즐 패턴, 언어 상식에서도 줄줄이 오답
새 벤치마크로 특훈... 5년 내 AGI 나올까
똑똑한 인간 1000명이 낸 '마지막 시험'
o1, 딥시크R1, 제미나이 모두 10점 미만
퍼즐 패턴, 언어 상식에서도 줄줄이 오답
새 벤치마크로 특훈... 5년 내 AGI 나올까
편집자주
우주, 인공지능, 반도체, 바이오, 에너지 등 첨단 기술이 정치와 외교를 움직이고 평범한 일상을 바꿔 놓는다. 기술이 패권이 되고 상식이 되는 시대다. 한국일보는 최신 이슈와 관련된 다양한 기술들의 숨은 의미를 찾고 사회에 미치는 영향을 심층 분석하는 '테크 인사이트(Tech Insight)'를 격주 금요일 연재한다.
인공지능(AI)이 어려운 문제를 푸는 모습을 주제로 설정하고 생성형 AI를 이용해 그린 그림. 달리3·신혜정 기자
“아냐, 나 포기할래(No, I give up).” 최근 등장한 성능 시험(벤치마크1)에서 인공지능(AI) 모델이 문제를 풀다가 ‘중도 포기’ 선언을 했다. 여러 벤치마크에서 줄곧 90점을 받았던 1등 AI 모델이 새로운 시험에서 단 한 문제 빼고 모두 오답을 내는 이변도 생겼다.
하루가 멀다 하고 똑똑해지던 AI가 좌절하게 된 건, 모델의 한계를 시험하기 위해 인간이 작정하고 만든 새로운 벤치마크 때문이다. 생성형 AI의 지적 능력은 이미 인간을 뛰어넘었다. 전문가들은 다음 단계인 인공일반지능(AGI)으로서의 능력을 확인할 새 벤치마크를 만들고 있다. 주목할 점은 AI가 박사급 문제만 모은 초고난도 시험뿐 아니라, 일반상식 퀴즈에서도 고전을 면치 못했다는 것이다.
우등생 AI 좌절시킨 '역대급' 벤치마크
지난 7일(현지시간) 미국 스탠퍼드대 인간중심 인공지능연구소(HAI)가 발표한 ‘AI 인덱스 2025’는 “AI를 시험하기 위한 더 도전적인 벤치마크가 꾸준히 출시되고 있다”는 점을 강조했다. AI가 기존 벤치마크를 이미 정복했기 때문이다. AI 벤치마크 중 가장 널리 쓰이는 건 ‘대규모 다중작업 언어 이해(MMLU)’다. 대학생 수준에서 과학·공학·인문학 등 57개 분야의 지식을 평가하는 문제가 담겼다. 인간이 풀면 정확도가 89.8%인데, AI는 이미 이를 뛰어넘었다. 오픈AI의 추론형 AI 모델 o1은 지난해 9월 92.3%를 기록했다.
미국의 비영리단체 AI안전센터(CAIS)와 스타트업 스케일AI가 지난 1월 공개한 벤치마크는 문제 난도를 박사급으로 올렸다. 벤치마크의 이름은 ‘인류의 마지막 시험(HLE·Humanity’s Last Exam)’, 인간이 AI에게 낼 수 있는 가장 어려운 문제라는 뜻이다. 시험 문제는 50개국 500여 기관의 교수와 연구자 약 1,000명이 출제했다. 수학과 물리학, 언어학 등에 이르기까지 대학원 수준의 교육을 받아도 풀기 어려운 문제들만 엄선했다.

인류의 마지막 시험 예시문제. 그래픽=송정근 기자
o1은 이 시험에서 정확도 8.8%를 기록했다. MMLU 벤치마크에서 100점 만점에 92점을 받은 우등생이 HLE에서는 8점을 받은 것이다. 중국 스타트업 딥시크의 추론형 모델 R1과 구글 제미나이 2.0도 각각 8.6%, 7.2%를 기록해 HLE의 '역대급' 난도가 증명됐다.
인공지능보다 인간에게 유리한 문제
AI에게 도전적인 벤치마크가 반드시 사람에게도 어려운 것은 아니다. 오히려 사람이 쉽게 푸는 문제에서 AI가 막히는 경우도 많다. 지난 2월 미국 노스웨스턴대 연구진이 ‘박사급 지식은 필요 없다’는 논문을 통해 공개한 ‘주간추론(RW·Reasoning Weekly)'이라는 벤치마크가 대표적이다. 연구진은 미국 공영방송 NPR 라디오에서 매주 일요일 방송하는 퀴즈 600개를 사용해 벤치마크를 만들었다. 주로 언어 상식 문제로, “미국에서 태어나 자란 성인이라면 충분히 이해할 수 있는 수준”이라는 게 연구진의 설명이다.

주간 추론 예시 문제. 그래픽=송정근 기자
AI 모델들은 RW 벤치마크에서 줄줄이 오답을 냈다. 연구진이 테스트한 14개 모델의 평균은 100점 만점에 27.6점. 가장 높은 성적을 낸 o1의 정확도가 61%였고, 챗GPT4는 6%에 그쳤다. AI 모델들은 퀴즈를 풀다가 포기 선언을 하기도 했다. 연구진은 딥시크R1과 미국 스타트업 앤스로픽의 AI 모델 클로드 소네트가 각각 142번과 18번의 포기를 했다고 밝혔다. RW 벤치마크에서 36% 정확도를 보인 R1은 오랜 시간 동안 답을 내지 못한 채 추론을 거듭하다가 ‘포기할래’란 메시지를 내놓거나, 문제의 주요 요건을 무시한 채 엉뚱한 답을 내놓기도 했다.
대학 수준 문제를 너끈히 풀던 AI가 고전한 이유는 일반 상식을 습득하는 데 생각보다 많은 노력이 필요하기 때문이다. 이진식 LG AI연구원 엑사원랩장은 “상식 습득을 위해서는 상당히 넓은 범위의 지식이 필요한데, 학습 데이터에 누락돼 미처 다뤄지지 않는 경우가 많다”고 설명했다.
주목할 점은 RW 벤치마크에서 추론형 AI의 정확도가 비추론형 AI보다 높았다는 것이다. 수능 국어 벤치마크를 만든 스타트업 마커AI의 정철현 대표는 “추론형 AI는 정답을 찾는 과정에서 자가 검증과 오류 수정을 한다는 차이가 있다”며 “비추론형은 한번 생각을 시작하면 환각도 알아차리지 못하는 반면 추론형에선 실수가 크게 줄었다”고 말했다. 하지만 그런 추론형 AI 모델조차 지난달 24일 등장한 새 벤치마크 ‘ARC-AGI-2’에서는 맥을 추지 못했다. 구글 출신 딥러닝 전문가인 프랑수아 숄레가 창립한 국제 비영리재단 ARC는 “인간처럼 생각하는 AGI 개발을 가속화하기 위해” 이 벤치마크를 만들었다.
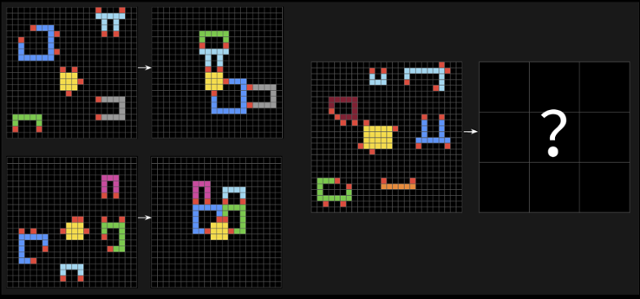
ARC-AGI-2 벤치마크의 문제 예시. 왼쪽에 제시된 패턴을 보고 물음표에 들어갈 모양을 추론하면 된다. ARC재단 홈페이지 캡처
ARC-AGI-2의 문제들은 인간이 배경지식 없이도 직관과 추론으로 풀 수 있는 것들이다. 네모난 퍼즐의 패턴을 통해 상징이나 맥락을 파악해 답을 예측하는 방식이기 때문이다. 인간 패널이 이 시험을 봤을 때 정확도는 60%였는데, o1은 4.0%, 딥시크R1은 1.3%로 바닥을 쳤다. ARC재단은 벤치마크에 ‘효율성’ 지표를 도입해 이 같은 결과가 나왔다고 밝혔다. AI가 답을 찾기 위해 엄청난 컴퓨팅 파워에 의존해 무차별적으로 여러 패턴을 대입하는 것을 차단했다는 뜻이다. 또 문제를 풀기 위해 암기 대신 패턴을 즉석에서 해석해야 하는 것도 AI에겐 큰 장벽이었다는 설명이다.
어떤 모델이 AGI에 먼저 가까워질까
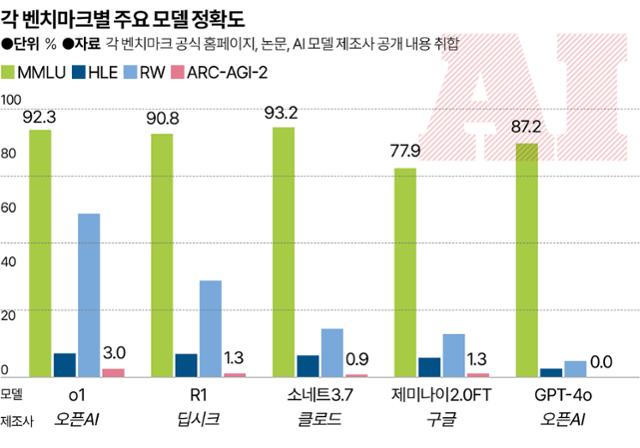
각 벤치마크별 주요 모델 정확도. 그래픽=송정근 기자
비록 AI 모델들을 시험에 들게 했지만, 새로운 벤치마크는 AI 발전을 위해 꼭 필요하다. 이진식 엑사원랩장은 “기존 벤치마크가 차례차례 정복되고 있기 때문에 점점 더 풀기 어려운 것을 제안해야 현재 기술의 한계점을 파악하고 더 발전시킬 수 있다”고 말했다.
새 벤치마크로 특훈을 한 덕에 ‘2030년 이전’으로 예상되는 AGI 등장 시기가 더 빨라질 수도 있다. HLE 연구진은 “올해 말이면 AI 모델들의 정확도가 50% 이상이 될 것”이라고 전망했다. 구글이 지난달 공개한 제미나이 2.5는 실험 버전임에도 HLE에서 18.2%를 기록해 기존 모델보다 높은 성적을 냈다. 그렉 캄라트 ARC재단 대표는 “인간에게는 쉽지만 AI에게는 어렵거나 불가능한 도전 과제를 끊임없이 제시해 AGI를 향한 혁신 기간을 크게 단축할 수 있을 것”이라고 말했다.
1
벤치마크인공지능 모델의 성능을 비교 평가하기 위해 만들어진 테스트 기술 체계.