
'가성비 AI' 시대 열어
작업량 축소·MoE모델로 비용 절감
탄탄한 중국 AI 생태계
"마윈 키드처럼 딥시크 키드 등장할 것"
작업량 축소·MoE모델로 비용 절감
탄탄한 중국 AI 생태계
"마윈 키드처럼 딥시크 키드 등장할 것"

엔비디아의 최신 GPU ‘H100’은 8700만원(6만 달러)에 거래된다. 반도체 하나가 고급 승용차 한 대와 맞먹는다. 출고가격은 3만~4만 달러지만 구하기 힘들어서 실거래가격은 두 배로 뛴다.
이걸 최소 1만6000개는 쏟아부어야 챗 GPT나 라마 같은 AI 모델을 학습시킬 수 있다. 이후 데이터센터 운영 비용이나 유지 비용은 별도다.
전문가들은 현재 우리가 사용하는 AI 거대언어모델(LLM)의 발전은 AI 알고리즘의 진화가 아니라 반도체 기술의 진화 때문이라고 말한다. 빠른 행렬 곱셈으로 수많은 데이터를 학습하고 처리할 수 있는 반도체가 개발되면서 생성형 AI가 탄생했기 때문이다.
미국 빅테크가 AI 개발을 위해 수십조원을 쏟아붓고도 매년 투자 계획을 상향하는 이유다. 더 좋은 반도체를 더 많이 집어넣을수록 성능이 좋아지고 기술 패권을 잡을 수 있다고 믿어온 시장이었다.
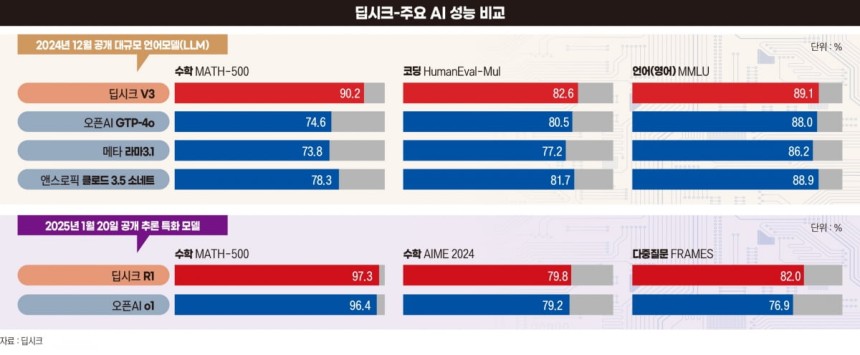
중국 AI 스타트업 딥시크는 이 공식을 깼다. 고성능칩이 아니라 저렴하지만 성능은 떨어지는 H800을 딱 2048개만 써서 챗GPT 수준의 AI 모델을 내놨다. 엔비디아의 비싼 칩을 1만6000개나 사지 않아도 된다는 걸 딥시크가 증명하면서 엔비디아 주가는 한때 17% 폭락했다.
화웨이 칩을 활용한 딥시크그간 중국에 반도체 수출을 제한해 온 미 정부는 물론 AI 개발에 천문학적 금액을 쏟아붓던 미 빅테크(거대 기술기업)들이 큰 충격에 빠졌다. 딥시크는 모델 실행 단계인 추론에 화웨이 칩(어센드 910C)을 활용하는 것으로 알려졌기 때문이다.
미국뿐만 아니라 한국도 한 방 맞은 분위기다. 한국 대표 기업들은 미국 빅테크에 ‘간택’당하기만을 손꼽아 기다려왔는데 2030세대 140명이 모인 중국의 스타트업 하나가 판을 뒤집었다. 2023년 7월 설립된 딥시크가 1년 반 만에 이룬 성과다.
딥시크는 개발 및 운영 비용을 혁신적으로 절감했다. 그 핵심은 ‘작업량 축소’다. 컴퓨터는 32개의 0 또는 1, 즉 32비트의 부동소수점으로 표현해 연산한다. 딥시크는 이걸 압축해 8비트로 확 줄였다. 그러면 데이터가 간단해지고 연산이 빨라진다.
메모리 사용량도 줄어들어 고성능 칩이 필요 없고 데이터 사용료도 감축할 수 있다. 연산이 빨라지는 대신 정밀도가 떨어질 수 있는데 딥시크는 메모리 사용량을 75% 줄이면서도 정확도를 해치지 않았다고 주장한다.
데이터 학습도 효율적으로 한다. 딥시크는 자신의 학습 데이터를 여러 전문 영역으로 구분해 나눠 두고 질문이 들어오면 해당 특정 영역만 활성화해 답한다. 이른바 ‘전문가 혼합(MoE·Mixture of Experts)’ 모델이다.
예컨대 회사에서 10명씩 속한 2개의 팀이 함께 협업한다고 하면 20명이 모두 소통하며 일하는 것이 아니라 해당 분야에 전문성을 가진 팀장 2명만 소통하도록 하는 것이다. 이렇게 하면 데이터 학습 시에도 비용과 시간을 크게 절약할 수 있다. 반면 기존 빅테크의 AI 모델은 모든 영역을 활성화해 답을 내놓는다.
딥시크에 눈돌리는 미국 빅테크딥시크의 ‘가격 파괴’는 AI 시장 전체를 흔들었다. 딥시크 ‘R1’ 모델의 API 가격은 100만 개의 출력 토큰당 2.19달러다. 오픈AI의 ‘o1’ 모델 API 가격은 출력 토큰 100만 개당 60달러다. 가격이 30배 가까이 차이 나는 것이다.

그러자 오픈AI는 성능보다 경제성을 극대화한 ‘o3-mini’를 내놨다. o3-mini의 가격은 출력 토큰 100만 개당 4.40달러다. 하지만 딥시크에 비해 여전히 비싼 수준이다. 폐쇄형인 오픈AI와 달리 딥시크는 누구나 소프트웨어 소스 코드를 수정하고 배포할 수 있는 오픈소스 방식으로 공개했다.
중국이 미국을 상대로 ‘전면전’을 선포한 꼴인데 미국 빅테크들은 반대로 딥시크 AI 모델을 자사 서비스에 탑재하기 시작했다.
엔비디아는 자사 AI 플랫폼인 ‘NIM 마이크로서비스’에서 딥시크의 R1 모델을 지원한다고 밝혔다. NIM 마이크로서비스는 엔비디아의 그래픽처리장치(GPU)에 기반한 클라우드 플랫폼으로 이를 통해 생성형 AI 모델을 개발해 배포할 수 있다.
마이크로소프트(MS)의 클라우드 서비스인 애저에서도 R1 모델을 사용할 수 있게 됐고, 아마존웹서비스(AWS)는 R1 모델을 활용할 수 있도록 지원한다고 밝혔다. AI 검색 플랫폼인 퍼플렉시티도 딥시크를 도입했다.

전문가들은 딥시크로 인해 미국 소수 빅테크가 독점하던 AI 시장에 변화가 올 수 있다고 말한다. 전병서 중국경제연구소장은 “딥시크에 이어 알리바바도 새로운 모델을 출시했고 AI 모델 가격을 97% 인하한 상황이며 바이두, 텐센트 등도 이를 따라갈 추세”라며 “이렇게 되면 기술개발 선두는 미국, 대중화는 중국이라는 공식이 출현할 가능성이 있다”고 말했다.
세상을 뒤집어 놓은 딥시크의 목표는 따로 있다. 량원펑 딥스크 창업자는 지난해 7월 중국 언론매체와의 인터뷰에서 “딥시크는 가격 전쟁에 관심이 없으며 인공일반지능(AGI)을 달성하는 것이 회사의 목표”라고 말했다.

미국 빅테크들 역시 중국의 가격 전쟁에도 오히려 투자 규모를 늘렸다. 오픈AI는 지난해 10월 민간 투자금 유치 사상 최대 규모인 66억 달러 조달에 성공한데 이어 불과 3개월 만에 6배에 달하는 투자금을 끌어모으고 있다.
메타도 올해 AI 인프라 구축 투자비 650억 달러(약 95조원)를 예정대로 집행하기로 했다. 마이크로소프트는 올해 최대 800억 달러(약 116조원)를 AI에 투자한다는 계획이다. 구글 모회사 알파벳은 올해 AI 인프라 등에 약 750억 달러(109조원)를 투자할 것이라고 밝혔다. 이는 시장 추정치인 597억3000만 달러를 25% 상회하는 수치다.인터뷰-전병서 중국경제연구소장
“AI까지 점령한 중국의 ‘식칼 신공’”

사진=한경비즈니스
“딥시크는 끝이 아닌 시작이다. 흙수저 마윈의 성공 이후 수천, 수만의 ‘마윈 키드’가 등장한 것처럼 ‘딥시크 키드’가 대거 등장할 가능성 크다.”
전병서 중국경제연구소장은 딥시크 개발 이후 중국의 기술 발전에 가속도가 붙을 것이라고 전망한다. 미국의 봉쇄가 강화될수록 제재의 역설이 작용하면서 AI 생태계가 진화하고 있기 때문이다.
반도체 산업과 중국 경제 관련 손꼽히는 ‘중국통’인 전 소장은 여의도 금융가에서 17년간 반도체·정보기술(IT) 애널리스트로 활약했다. 애널리스트 시절엔 ‘한경비즈니스 베스트 애널리스트’로도 수차례 선정되며 반도체 전문가로 이름을 떨쳤다. 이후 중국 베이징 칭화대 석사, 상하이 푸단대 박사학위를 받았다. 다음은 그와의 일문일답.
-딥시크가 산업계에 던지는 의미는 무엇인가.
“‘AI판 테무’가 등장한 것이다. 그간 한국의 D램 업체들이 최첨단 EUV 장비로 대충 설계해서 기계의 힘으로 반도체 만들다가 구식장비로 공정 개선해서 제품을 만들어낸 마이크론이나 중국의 창신메모리테크놀로지(CXMT) 같은 후발업체에 뒤통수 맞은 것과 같은 현상이 미국에서도 일어난 것이다. 미국 AI 업계도 모델 개선보다 첨단 AI 반도체 투입에만 경쟁적으로 나서다가 ‘대륙의 실수’가 나온 것이다.”
-미국의 제재에도 중국의 AI, 과학기술이 발전하는 이유는 무엇인가.
“미국의 반도체 수출 통제는 이미 중국의 ‘식칼 신공’에 모두 구멍이 뚫렸다. 회칼이 없으면 식칼로라도 만들어내는 기술 근성이다. 그간 미국이 실시했던 미국의 대중국 14나노(nm) 파운드리, 18nm D램, 128단 낸드, AI 반도체 수출 통제가 이뤄지면서 오히려 제재의 역설이 작용했다.”
-첨단 장비나 첨단 반도체 없이 이룬 성과다.
“미국 바이든 정부는 2022년 10월부터 14nm 이하 파운드리, 18nm 이하 D램, 128단 이상 낸드 장비와 기술을 중국으로 수출하는 것을 금지했다. 2023년 10월에는 엔비디아의 첨단 AI칩도 중국 수출을 금지하고 H800 같은 저사양의 제품만 수출을 허가했다. 그런데 화웨이와 SMIC는 7나노 반도체 양산에 성공했다. 화웨이는 2020년 트럼프 행정부의 제재로 첨단 나노 공정이 요구되는 AP를 살 수 있는 길이 끊겼다.
네덜란드 장비 업체인 ASML은 EUV 노광장비에 이어 2023년 9월 1일부터는 이보다 낮은 단계인 심자외선(DUV) 노광장비의 중국 수출도 중지했다. 그런데 문제는 SMIC는 보유하고 있던 DUV로 화웨이의 7나노 공정 스마트폰 칩 양산에 성공한 것이다. 이런 ‘식칼 신공’이 AI 기술에도 적용됐다.”
-중국에 유독 AI 인재가 많은 이유가 무엇인가.
“스티브 잡스 같은 괴팍한 인재 하나가 회사를 먹여 살리고 나라를 먹여 살리고 세상을 바꾸는 시대다. 이런 시대에 중국의 영재(英才)교육이 AI 시대에 묘하게 맞아떨어졌다. ‘중국의 엔비디아’로 불리는 중국 AI칩의 대명사 한무기(cambricon) 역시 16세에 중국 과기대 영재반에 입학한 1985년생 CEO 천톈스가 창업한 회사다. 딥시크는 17세에 대학을 들어간 85년생 수학 천재 CEO가 만든 AI 회사다.
중국의 대입제도가 다시 중국 과학기술의 신 부흥시대를 열고 있다. 연간 1200만 명의 대졸자 중 600만 명이 이공계다. 이러한 이공계 인재가 중국 AI 기술 생태계의 중추다. 2022년 기준 세계 최고 AI 인재의 47%가 중국에서 왔다. AI 관련 논문의 인용비중도 중국이 미국을 추월했다.”